
I’ve spent several years working on an Alpine-based OS for personal infrastructure. Its design goals are:
- OS is small and fully in RAM, and a single image is used for all nodes.
- The OS is easy to keep in your head and modify as needed.
- Upgrading the OS is easy.
- Nodes can boot and configure themselves over the network, but the network is not required for booting
- Configuration is kept in source control.
- Drift is kept in check because machines do not keep state except for explicitly mounted directories.
This is a whirlwind tour of what it is and how it works. It’s written for anyone who might want to customize the way their OS gets built and deployed. I didn’t start out understanding how Alpine’s init system or APK package repositories worked, and it was really exciting to realize that I could learn enough to make changes to them.
What I’m describing here isn’t at all generic enough for someone else to want to use directly. As it is in its git repo, it’s only useful to me. But, in my opinion, the best thing about computers is the power to change whatever you want. I hope that someone will read this and find the individual changes or techniques useful, even if the sum isn’t.
I’m going to show it from the perspective of how I use it, and link to implementation details. When linking to implementation details, sometimes I’ll link to the tip of the master branch (which will point to new commits as I make them) alongside a link to a specific commit (which will continue to work even in the future if my master branch changes significantly).
What I should have been working on instead
In 2022, I joined Indeed as a site reliability engineer, and since Indeed deploys virtually all its services on Kubernetes I wanted to get more hands on experience with it. I am very interested in home clusters, so I started working on a tiny bare metal cluster in my office called kubernasty, keeping public kubernasty lab notes. I was tearing down the cluster and starting over a lot, and I wanted a reproducible way to create it from scratch.
Unfortunately, once I started working on this, I found it far more interesting than working on the cluster itself, and I’ve gotten side tracked onto two major projects. One of those side track projects is progfiguration, an “infrastructure as code, but like, actual code” framework for writing system configuration that uses vanilla Python instead of YAML. The other side track project is psyopsOS, which is what this post is about.
Booting the OS
When the OS boots, it displays the GRUB menu over both video console and serial.
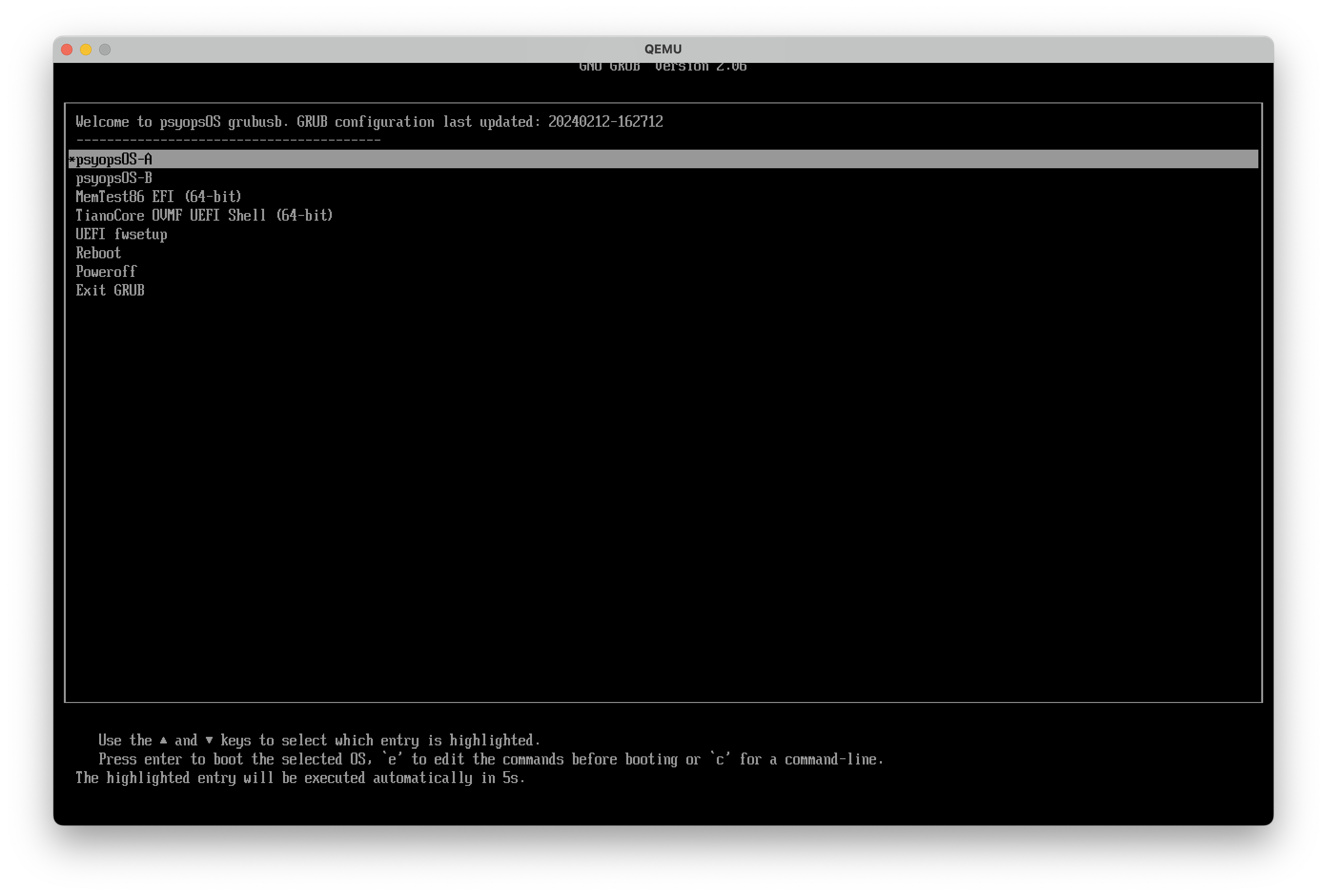
It boots one of the psyopsOS-A and psyopsOS-B partitions –
this allows a booted operating system to update the other side without disruption.
It also offers some tools like memtest and the UEFI shell.
The A and B partitions are not root filesystems; they contain just a kernel and a squashfs root filesystem, along with supporting files like System.map, modloop, etc.
When they boot, the squashfs gets loaded into RAM.
It works just like any other Alpine system with a RAM-backed root filesystem.
Changes don’t persist back to the squashfs,
but most machines do have some persistent storage mounted to /psyopsos-data.
Updating the OS
The first versions of this idea used custom Alpine ISO images written to USB disks. I had heard that gokrazy had A/B updates, and I wanted this but couldn’t think of how to implement it with my ISO-based system. The solution literally came to me in my sleep: don’t build an ISO, but build the same artifacts that the ISO builds (squashfs root filesystem kernel, etc) and boot them via GRUB. GRUB gets installed to the EFI System Partition (ESP), and small utilities like memtest can be installed there too.
Updates are verified via minisign(1)
and distributed via S3.
I wrote a program called neuralupgrade
(master,
0ab6895)
to apply updates.
It can be used to see the latest version of the operating system (A/B partitions) or EFI System Partition on the update repository:
agassiz:~# neuralupgrade show latest
latest:
https://psyops.micahrl.com/os/psyopsOS.grubusb.os.latest.tar.minisig:
type: psyopsOS
filename: psyopsOS.grubusb.os.20240209-220437.tar
version: 20240209-220437
kernel: 6.1.77-0-lts
alpine: 3.18
https://psyops.micahrl.com/os/psyopsOS.grubusb.efisys.latest.tar.minisig:
type: psyopsESP
filename: psyopsOS.grubusb.efisys.20240209-220444.tar
version: 20240209-220444
efi_programs: memtest64.efi,tcshell.efi
and apply it to the nonbooted side:
agassiz:~# neuralupgrade apply nonbooted efisys --os-version latest --esp-version latest
neuralupgrade INFO Updated nonbooted side psyopsOS-B with /tmp/psyopsOS.grubusb.os.20240209-220437.tar at /mnt/psyopsOS/b
neuralupgrade INFO Updated efisys with /tmp/psyopsOS.grubusb.efisys.20240209-220444.tar at /mnt/psyopsOS/efisys
and show whether a particular partition has a particular version
agassiz:~# neuralupgrade check --target a --version latest
a: psyopsOS-A is currently version 20240202-212117, not version 20240209-220437
My goal is to make it very safe to apply updates. What I’d really like is fully atomic updates, where there is no power outage that could cause a nonbooting system. I don’t quite have that with this design, but it’s maybe as close as I could come without maintaining my own bootloader. The upgrade script doesn’t change the partition layout, so the disk itself shouldn’t be trashed. It fully updates the nonbooting partition before modifying the GRUB configuration, and it renames the new configuration on top of the old one (after backing up the old one first), so the window for a trashed ESP is very small. In normal operation, all partitions on the boot disk are mounted read-only.
Node configuration
The A/B OS partitions and the EFI System Partition are the same for all nodes.
There is a fourth partition, called psyops-secret,
that handles rarely-changed node specific information,
including the node name, SSH host keys, decryption keys, etc.
When the node boots, it mounts this partition,
and runs a progfiguration site package
to configure itself.
The files required for this are described in
System secrets and individuation.
My progfiguration site package
(master,
5720e4b)
contains a script called progfiguration-blacksite-node
(master,
5720e4b)
that can generate all of this in one command with
> progfiguration-blacksite-node new -h
usage: progfiguration-blacksite-node new
[-h] [--force]
[--outdir OUTDIR | --outscript OUTSCRIPT | --outtar OUTTAR]
[--hostname HOSTNAME] [--flavor-text FLAVOR_TEXT]
--psynetip PSYNETIP
[--psynet-groups PSYNET_GROUPS [PSYNET_GROUPS ...]]
[--mac-address MAC_ADDRESS] [--serial SERIAL]
nodename
Progfiguration is beyond the scope of this post, but it has extensive documentation.
To launch progfiguration, when I build the root filesystem squashfs image,
I drop in a local.d script
(master,
30366ce).
The psy0 interface
Included in the secret partition is a mactab file
containing a mapping of a MAC address found on the machine to a psy0 interface.
This is copied to /etc/mactab in the local.d script
and read by nameif(1) in Alpine to assign my NIC that name.
Some hardware doesn’t enumerate its NICs the same way on every boot or every kernel version,
meaning what is eth0 on one boot could become eth1 on a subsequent boot;
this works around that issue.
Decentralized
It’s really important to me that nodes could boot up without Internet access, or if one of my services is down. Furthermore, I don’t want to keep private keys on hardware I don’t control, which makes centralized services harder. In fact, it would ideally not rely on centralized services at all.
This is why the machines aren’t booted over the network. It also informs the design of deaddrop, which contains both APK and operating system update repositories.
deaddrop repository
“deaddrop” is the name of the S3 bucket that contains APK repositories and operating system updates.
The build system can
forcepull all files from deaddrop to the local cache,
or forcepush all files from the local cache to deaddrop.
For OS updates, I added some neat functionality that copies local symlinks to S3 as redirect objects,
meaning I can have a symlink for the latest version of an update
which gets converted during forcepush to HTTP 301 redirects,
and vice verse for forcepull.
I’ve already written a blog post about this:
Local symlinks as HTTP redirects in S3.
Building Alpine APK packages
Alpine’s APK packages are simple to understand, and there are hundreds of examples you can reference in the aports repository, and useful documentation on the wiki too.
I currently build three APK packages:
psyopsOS-base(master, 2879ee6), which handles things I want done before mylocal.dscript starts more heavyweight customization, like set the root password.neuralupgrade(master, 2879ee6), which applies operating system and EFI System Partition updates, both on live systems and when building disk images.progfiguration_blacksite(master, 5720e4b), which is an APK of my progfiguration site package.
I have some recommendations for custom APK repositories.
telekinesis: the build system
This is a Python package I use for building and running psyops tasks.
It’s sort of like an argparse version of
ansible-playbook(1) + make(1).
> tk --help
usage: tk [-h] [--debug] [--verbose] {showconfig,cog,deaddrop,builder,mkimage,buildpkg,deployos,vm,psynet,signify} ...
Telekinesis: the PSYOPS build and administration tool
positional arguments:
{showconfig,cog,deaddrop,builder,mkimage,buildpkg,deployos,vm,psynet,signify}
showconfig Show the current configuration
cog Run cog on all relevant files
deaddrop Manage the S3 bucket used for psyopsOS, called deaddrop, or its local replica
builder Actions related to the psyopsOS Docker container that is used for making Alpine packages and ISO images
mkimage Make a psyopsOS image
buildpkg Build a package
deployos Deploy the ISO image to a psyopsOS remote host
vm Run VM(s)
psynet Manage psynet
signify Sign and verify with the psyopsOS signature tooling
options:
-h, --help show this help message and exit
--debug, -d Open the debugger if an unhandled exception is encountered.
--verbose, -v Print more information about what is happening.
A few examples
# Build a generic disk image in Docker
tk mkimage grubusb --stages kernel squashfs efisystar ostar diskimg
# Boot a VM of 'qreamsqueen', my test psyopsOS VM
tk vm profile qreamsqueen
# Prepare Docker for building a generic disk image,
# but don't actually build anything;
# instead, drop into a shell inside the docker container
tk mkimage grubusb --interative grubusb
# Build APK packages, and also build neuralupgrade as a pyz/zipapp package
tk buildpkg base blacksite neuralupgrade-apk neuralupgrade-pyz
# Remove all files in the local deaddrop cache, and download all files into it from S3
tk deaddrop forcepull
# Remove all files in the S3 bucket, and upload all files from the cache to the bucket
tk deaddrop forcepush
Why telekinesis?
I iterated through several build systems,
and I ended up on a bespoke Python program
(what a surprise).
I started with make(1),
then Invoke with a single tasks.py,
then a whole tasks module with several files,
and finally wrote telekinesis
(master,
43e3527).
I’d really like to add make(1)-style build dependencies,
so that the tool will automatically rebuild artifacts
when the source files they depend on are changed.
To be honest, if Invoke had that feature,
I probably wouldn’t have changed away from it.
I probably should have more thoroughly investigated other build systems
like scons or something built on ninja,
but I didn’t.
Building new OS update packages
I build new OS update packages with telekinesis.
There are several distinct components that it can build, called “stages”.
> tk mkimage grubusb --list-stages
grubusb stages:
mkinitpatch Generate a patch by comparing a locally created/modified
initramfs-init.patched.grubusb file (NOT in version control)
to the upstream Alpine initramfs-init.orig file (in version
control), and saving the resulting patch to initramfs-
init.psyopsOS.grubusb.patch (in version control). This is only
necessary when making changes to our patch, and is not part of
a normal image build. Basically do this: diff -u initramfs-
init.orig initramfs-init.patched.grubusb > initramfs-
init.psyopsOS.grubusb.patch
applyinitpatch Generate initramfs-init.patched.grubusb by appling our patch
to the upstream file. This happens during every normal build.
Basically do this: patch -o initramfs-init.patched.grubusb
initramfs-init.orig initramfs-init.psyopsOS.grubusb.patch
kernel Build the kernel/initramfs/etc.
squashfs Build the squashfs root filesystem.
efisystar Create a tarball that contains extra EFI system partition
files - not GRUB which is installed by neuralupgrade, but
optional files like memtest.
efisystar-dd Copy the efisystar tarball to the local deaddrop directory.
(Use 'tk deaddrop forcepush' to push it to the bucket.)
ostar Create a tarball of the kernel/squashfs/etc that can be used
to apply an A/B update.
ostar-dd Copy the ostar tarball to the local deaddrop directory. (Use
'tk deaddrop forcepush' to push it to the bucket.)
sectar Create a tarball of secrets for a node-specific grubusb image.
Requires that --node-secrets NODENAME is passed, and that the
node already exists in progfiguration_blacksite (see
'progfiguration-blacksite-node save --help').
diskimg Build the disk image from the kernel/squashfs. If --node-
secrets is passed, the secrets tarball is included in the
image. Otherwise, the image is node-agnostic and contains an
empty secrets volume.
Customizing Alpine’s init
The init program on the initrd had to be modified from Alpine’s stock version.
This is the part of my system that I’m most worried about as Alpine makes changes upstream,
but it had to be done.
I keep the upstream init program and a patch containing my changes
in the psyops repo
(master,
d5224ce),
so that I can easily diff between the version I’m using and any new versions released by Alpine.
Alpine’s version is developed out of
the mkinitfs repo.
The easiest way to see the latest init is to crack open an initramfs
from a running Alpine system.
The patch file (master, d5224ce), is as simple as I could make it. It modifies the init script to read a kernel command line argument that GRUB passes to determine which A/B partition to load the root filesystem from, mounts that partition, and then continues on with upstream init behavior.
Running tk mkimage grubusb --stages applyinitpatch
will generate a patched init script called initramfs-init.patched.grubusb,
which is not committed to the repo.
It’s copied into the initramfs as /sbin/init by the kernel stage.
When I’m modifying the init script,
I start with initramfs-init.patched.grubusb,
make my change,
and then run tk mkimage grubusb --stages mkinitpatch
to generate the initramfs-init.psyopsOS.grubusb.patch file.
Building the squashfs
tk mkimage grubusb --stages squashfs calls
the script make-grubusb-squashfs.sh
(master,
36eacc4)
which builds a squashfs file.
It’s based on Alpine’s
genapkovl-dhcp.sh,
which creates an APK overlay file,
but it first uses apk add --initdb -p $tmpdir ...
and apk add -p $tmpdir ... alpine-base $other_packages ...
to install an Alpine root filesystem into $tmpdir.
Then, instead of creating a tar(1) archive as genapkovl-dhcp.sh does,
it runs mksquashfs on the $tmpdir instead.
And that’s it – that’s all you need to build an Alpine root filesystem.
Note that the squashfs doesn’t have a kernel or any kernel modules on it. Those are built separately, and loaded directly by GRUB from the A or B partition.
Building the kernel
tk mkimage grubusb --stages kernel calls
the script make-grubusb-kernel.sh
(master,
36eacc4)
which gets a kernel and modloop.
This works like
Alpine’s update-kernel.sh,
but doesn’t rely on it.
Building OS and ESP update tarballs
ostar tarballs are update tarballs that contain
a squashfs, a kernel, and other files like System.map etc.
They’re built with tk mkimage grubusb --stages ostar.
esptar tarballs are update tarballs that contain
any programs aside from GRUB to install on the EFI System Partition.
They’re built with tk mkimage grubusb --stages esptar.
These tarballs can then be copied to the local deaddrop cache with
tk mkimage grubusb --stages ostar-dd esptar-dd,
and then copied to the repository with tk deaddrop forcepush.
Once there, nodes anywhere on the Internet can pull down the update with
neuralupgrade apply --os-version latest --esp-version latest nonbooted efisys.
Building disk images
tk mkimage grubusb --stages diskimg calls
the script make-grubusb-img.sh
(master,
36eacc4)
which builds disk image files that can be written directly to a USB drive.
These disk images are not used for applying OS updates to existing systems, just for building a new boot disk.
The roles of minisign OS updates
minisign(1)
has a cool feature of “trusted comments”,
which are verified alongside the data of whatever is signed.
This gives us a good place to store metadata about an update.
An example minisig file:
untrusted comment: signature from minisign secret key
RURFlbvwaqbpRvnIwlbmffQCjHg4aX2v4ibj/xTUJddghpp4gPfTM3XGOemB9VPwiLBdsLmuLeSCrsj9ivsrzkcIepPKuD6BFgc=
trusted comment: type=psyopsOS filename=psyopsOS.grubusb.os.20240209-220437.tar version=20240209-220437 kernel=6.1.77-0-lts alpine=3.18
jYeKd4/nxxl+6fCx46Tv+WL2TT1zsKFWUGszXbZ5PWrTGbJtfMhlMoMaN1wKSJGpmCECFI45SrXvpiCDNG0UDA==
The trusted comment line contains key=value pairs that telekinesis asked it to sign.
neuralupgrade reads them and can show metadata about a signature file.
We keep a few versions of the OS in the update repository,
with filenames like psyopsOS.grubusb.os.20240209-220437.tar
and its signature file psyopsOS.grubusb.os.20240209-220437.tar.minisig.
We also keep an HTTP redirect from psyopsOS.grubusb.os.latest.tar.minisig
to whatever the latest minisig version is.
This means that neuralupgrade can retrieve the latest minisig file,
find the filename of the .tar it corresponds to in the metadata,
retrieve that file and verify it with the signature.
This has the nice property of avoiding race conditions
if a node is trying to retrieve an update
right when a new update is being added.
If I had instead relied on a *.latest.tar and a *.latest.tar.minisig,
the client might have pulled different versions
if it was working at just the wrong time.
The psynet overlay network
I wanted a way to access all the machines, even if I deploy them on different networks one day. I use nebula for this, and operate a couple of lighthouse nodes on Digital Ocean. Lighthouse nodes cannot access the network, just provide a way for nodes behind NAT to talk to one another.
I’d honestly prefer this to be Tailscale, but unfortunately Tailscale doesn’t have a good way to pre-generate a certificate for a node. Their reasoning is that key material should remain on the node it was generated on for security reasons, and while I think that makes sense in the general case, the design for psyopsOS is to have a centralized controller with access to all the secrets, so that nodes can be redeployed without reauthorization.
The end
Those are the major goals and features of the operating system.
To those of you undertaking a similar task, good luck. If you use anything from my project in yours, I’d love to hear about it.